Modelarchitecturen: de motor achter moderne AI
Modelarchitecturen: de motor achter moderne AI
Je hebt vast wel eens een AI-assistent gebruikt en je afgevraagd: hoe werkt dit eigenlijk? Hoe kan een systeem een vraag begrijpen, een tekst samenvatten of zelfs code schrijven? Het antwoord ligt voor een groot deel in de architectuur van het model — de manier waarop een AI-systeem intern is opgebouwd.
Op deze pagina lees je wat modelarchitecturen zijn, waarom ze belangrijk zijn en welke hoofdtypen je moet kennen. Je hebt hiervoor geen wiskundige of technische achtergrond nodig. Wel helpt het om te begrijpen dat niet elke AI hetzelfde in elkaar zit — en dat die opbouw bepaalt waarvoor een model geschikt is.
Nikki Bieleveldt
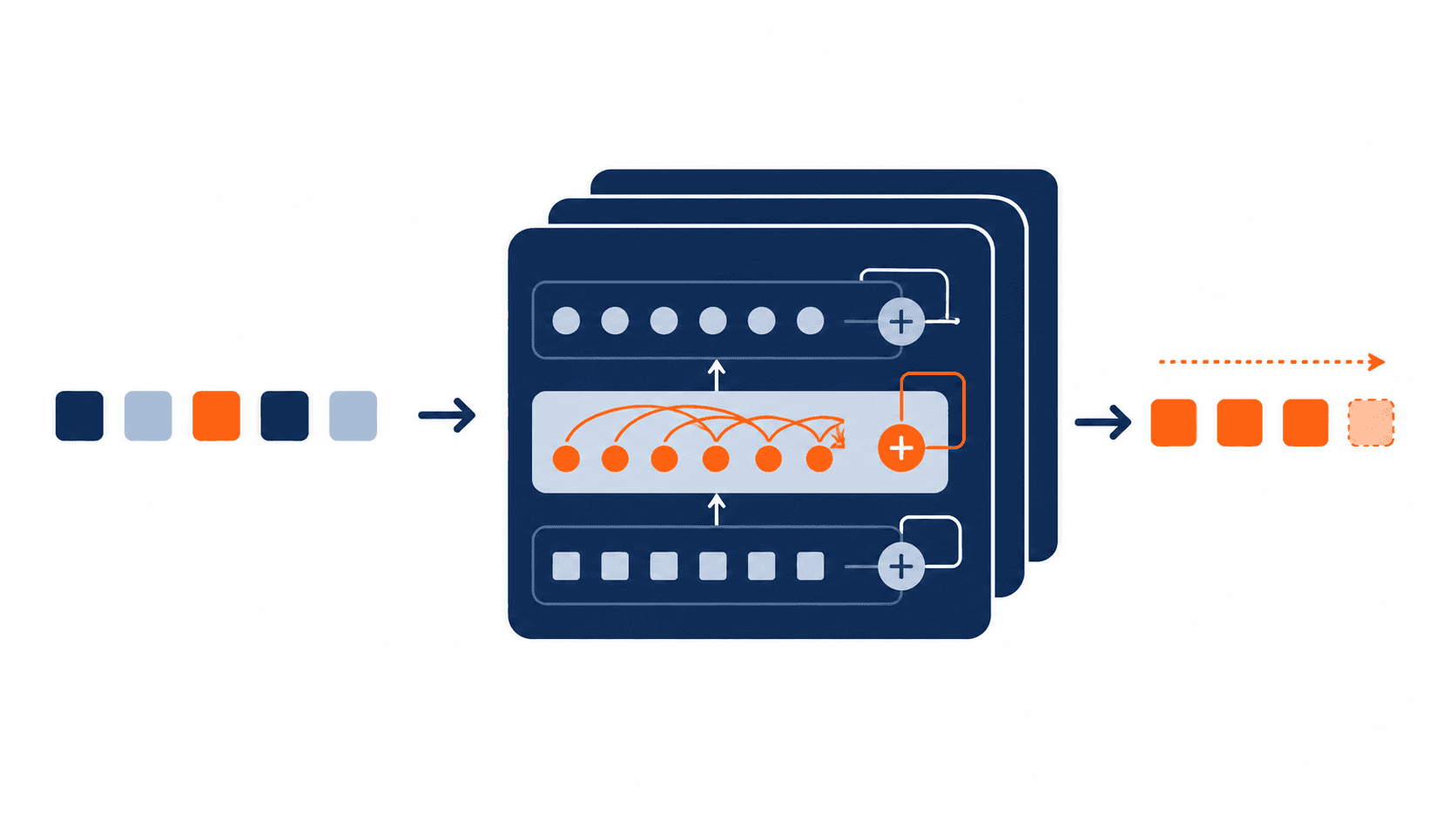
Wat is een modelarchitectuur?
Een modelarchitectuur is de blauwdruk van een AI-systeem. Het beschrijft hoe informatie door het netwerk stroomt: hoe een model invoer verwerkt, welke bewerkingen er plaatsvinden en hoe uiteindelijk een uitvoer wordt gegenereerd.
Vergelijk het met de architectuur van een gebouw. Een kantoorpand en een ziekenhuis zijn allebei gebouwen, maar ze zijn heel anders ontworpen — omdat ze verschillende functies vervullen. Zo zijn ook AI-modellen verschillend ontworpen afhankelijk van de taak: tekst genereren vraagt om een andere structuur dan het herkennen van gezichten of het analyseren van een tijdreeks.
De architectuur bepaalt:
- Wat voor soort data het model kan verwerken (tekst, beeld, audio, code)
- Hoe goed het model presteert op bepaalde taken
- Hoeveel rekenkracht en geheugen het nodig heeft
- Hoe het model getraind wordt
Waarom is dit belangrijk om te weten?
Als gebruiker of professional hoef je geen AI-model te bouwen om te begrijpen waarom architectuurkeuzes ertoe doen. Maar als je AI inzet voor concrete toepassingen — in je organisatie, in producten, in analyses — helpt basisinzicht je om betere keuzes te maken.
Niet elk model is geschikt voor elke taak. Een model dat is ontworpen om tekst te genereren, werkt anders dan een model dat is gebouwd voor classificatie. En een model dat goed is in het begrijpen van lange documenten, is niet automatisch goed in het voeren van een gesprek. Die verschillen beginnen bij de architectuur.
Een korte geschiedenis
AI-modellen bestaan al tientallen jaren, maar de afgelopen tien jaar heeft de ontwikkeling een enorme versnelling doorgemaakt. Een paar mijlpalen:
Neurale netwerken bestaan al sinds de jaren vijftig, maar kregen pas tractie toen rekenkracht goedkoper werd en grote datasets beschikbaar kwamen.
Convolutionele netwerken (CNN’s) zorgden begin jaren 2010 voor een doorbraak in beeldherkenning. Ze zijn geïnspireerd op de visuele cortex van het menselijk brein en verwerken afbeeldingen laag voor laag.
Recurrente netwerken (RNN’s) werden populair voor taalverwerking, omdat ze reeksen — zoals zinnen — stap voor stap kunnen verwerken. Ze hadden echter moeite met lange teksten en waren traag te trainen.
De transformer veranderde alles. In 2017 introduceerde Google een nieuw architectuurtype dat informatie parallel kon verwerken in plaats van stap voor stap. Dit maakte het mogelijk om veel grotere modellen te trainen op veel meer data. GPT, BERT, Claude en vrijwel alle moderne grote taalmodellen zijn gebaseerd op de transformer.
De belangrijkste architectuurtypen
Encoder-only modellen
Deze modellen lezen een stuk tekst en maken er een rijke, betekenisvolle representatie van. Ze zijn sterk in taken waarbij begrijpen centraal staat: tekstclassificatie, sentimentanalyse, zoeken in documenten.
Ze genereren geen nieuwe tekst, maar analyseren wat er al staat. Het bekendste voorbeeld is BERT, ontwikkeld door Google.
Decoder-only modellen
Deze modellen zijn ontworpen om tekst te genereren. Ze voorspellen woord voor woord wat er als volgende komt, op basis van alles wat er al staat. GPT-4, Claude en Llama zijn voorbeelden van decoder-only modellen.
Dit is het architectuurtype dat ten grondslag ligt aan de meeste chatbots en generatieve AI-toepassingen die je vandaag de dag gebruikt.
Lees meer over de decoder-only transformer →
Encoder-decoder modellen
Deze modellen combineren beide onderdelen. De encoder begrijpt de invoer, de decoder genereert de uitvoer. Dit maakt ze bijzonder geschikt voor taken waarbij je iets omzet van de ene vorm naar de andere: vertalen, samenvatten, of een vraag beantwoorden op basis van een document.
Voorbeelden zijn T5 (Google) en de originele transformer-architectuur uit 2017.
Convolutionele netwerken (CNN’s)
Lange tijd dé standaard voor beeldverwerking. CNN’s scannen afbeeldingen in kleine stukjes en herkennen patronen van eenvoudig naar complex — eerst randen, dan vormen, dan objecten. Ze worden nog steeds breed toegepast in medische beeldanalyse, gezichtsherkenning en kwaliteitscontrole.
Diffusiemodellen
Dit is het architectuurtype achter beeld- en audiogeneratie. Een diffusiemodel leert om ruis om te zetten in betekenisvolle output — een afbeelding, een geluidsfragment, een video. Midjourney, DALL·E en Stable Diffusion werken op basis van dit principe.
Multimodale modellen
De nieuwste generatie modellen combineert meerdere architecturen of breidt één basisarchitectuur uit om meerdere soorten data tegelijk te verwerken: tekst én beeld, audio én tekst, of zelfs video. GPT-4o en Gemini zijn voorbeelden van modellen die je kunt aanspreken via tekst, afbeelding of spraak.
Hoe verhouden architecturen zich tot modellen en tot training?
Het is handig om drie begrippen uit elkaar te houden:
Architectuur is de blauwdruk — de structuur van het netwerk, los van enige kennis.
Training is het proces waarbij het model leert: het krijgt enorme hoeveelheden data te zien en past zijn interne parameters aan totdat het goede voorspellingen maakt.
Model is het resultaat: de architectuur, gevuld met de kennis die het tijdens training heeft opgedaan.
Twee modellen met dezelfde architectuur maar getraind op verschillende data kunnen heel anders presteren. En andersom: twee modellen met verschillende architecturen kunnen — voor bepaalde taken — vergelijkbare resultaten geven.
De toekomst van modelarchitecturen
Architecturen zijn geen vaststaand gegeven. Onderzoekers blijven experimenteren met nieuwe structuren die efficiënter, sneller of capabeler zijn. Een paar ontwikkelingen om in de gaten te houden:
Mixture of Experts (MoE) is een aanpak waarbij een model bestaat uit meerdere gespecialiseerde subnetwerken. In plaats van altijd het volledige model te activeren, schakelt het systeem alleen de relevante experts in voor een gegeven taak. Dit maakt grote modellen efficiënter.
State space models zijn een alternatief voor de transformer die efficiënter omgaan met zeer lange teksten. Modellen als Mamba trekken hier aandacht mee in de onderzoekswereld.
Hybride architecturen combineren het beste van meerdere aanpakken — bijvoorbeeld transformers voor begrip en diffusie voor generatie.
Conclusie
Modelarchitecturen zijn de fundering van moderne AI. Ze bepalen wat een systeem kan, hoe het leert en waarvoor het geschikt is. Je hoeft geen ingenieur te zijn om dit te begrijpen — maar een basiskennis helpt je om AI-toepassingen beter te beoordelen, te kiezen en te begrijpen. De transformer, en met name de decoder-only variant, vormt vandaag de dag de kern van vrijwel alle grote taalmodellen die je dagelijks gebruikt.